刚爬了一本画册,正好借这个实例展示一下整个爬取过程,供感兴趣的朋友参考。这本画册的正文页面(包含对应页码图片的网页)URL形式为
http://www.abcabc.com/index.php/pages/category?Pages_page=pageid
- 网站网址马赛克一下,用abcabc代替;
- category:代表这本书在网站数据库里的编号;
- pageid:代表这个页面的页码。
爬取流程是个非常典型的蜘蛛流程:1. 获取所有页面,2. 获取页面上的图片地址,3. 按地址下载图片。
第一步 获取所有页面
在画册的介绍页面可以看到每一页的预览图,点进去看具体某一页的时候反而看不到完整的分页(有的网站会标明页数,有的网站在正文页面里会有完整的分页链接,可以据此查看总页数)。根据预览图提示可以知道这本书一共有44页,所以要做的就是抓取pageid为1~44的44个网页。
第二步 提取每个正文页面里的图片URL
一个网页上往往会有不计其数的图片、链接。如何得到自己要的关键信息,只能靠F12去分析网页,查看目标信息所在位置,本次案例里需要提取的是正文画页图片的URL,在http get获取到正文页面的源码后,有如下几个思路来提取所需的URL:
- 字符串处理(查找):查找特定特征的字符串——可以是元素id(id=”image”),可以是url固定的前导部分<img src=”https://www.abcabc.com/images/,甚至也可以是元素的行内样式(比如max-length=xxx)或者元素的css类名,通过特征字符串多次分割网页源码,最终提取到需要的URL;
- 字符串处理(正则):本质和上面一种方法一样,不过是通过正则表达式来查找特征字符串,而非字符串查找和切割;
- XML处理(XPATH):把HTML源码当作一个XML文档,根据层级结构定位,或者直接用筛选器来定位。

第三步 按URL下载图片
批量下载可以在代码里直接用http get完成,也可以把所有URL打印出来,复制到下载工具里下载。
有些网站的图片会用类似 https://www.abcabc.com/galleries/181818/1.jpg 的路径来保存,181818是comicid,1.jpg是相应页码的图片,不过话说回来,URL规则到这种程度,还写啥爬虫啊,F12拿到地址就可以直接批量下了。
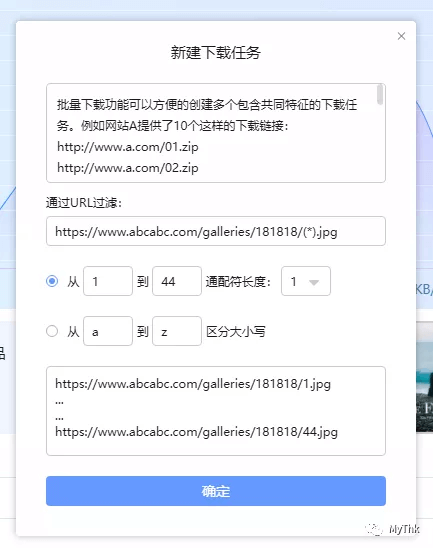
这次爬取的网站图片URL并不规则,直接以UUID命名(性价比极高的反爬手段),下载完成后只能得到一堆不规则文件名的文件,所以还需要再多加一步重命名处理。
第四步 重命名(不是每次都需要这个步骤)
当文件名不规则的时候,需要把每页图片按页码来重命名,做法也很多。如果直接在代码里用http get的方式下载图片,推荐在下载的时候直接用页面作为文件名保存文件。如果用下载工具进行下载的话,就需要提取URL的同时保存页码-文件名的映射关系,以便在下载完成后重命名。

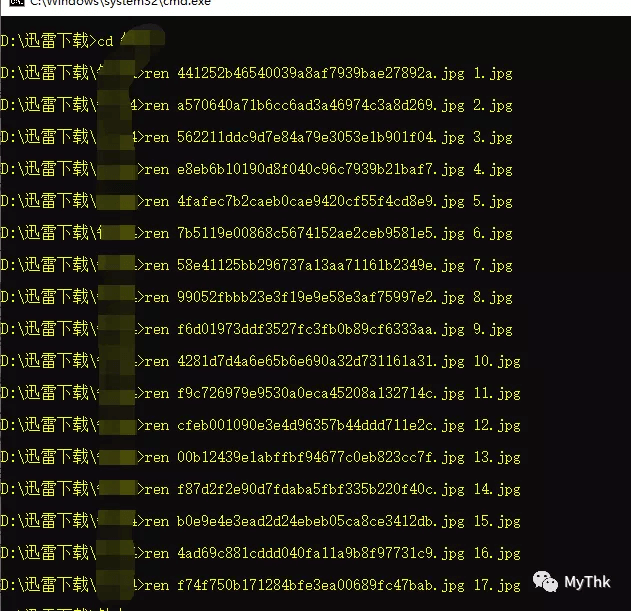
重命名的实现方式也不唯一,其中一种是在代码里直接生成批处理语句,把打印内容分完列以后,等所有图片下载完成,把重命名语句那列复制粘贴到命令提示符运行即可。
不过我在爬取的时候疏忽了,没有保存映射关系,只有一串URL,当然也不是没办法,URL列表其实已经隐含了页码和文件名的对应关系,第一条URL就是1.jpg,第二条就是2.jpg……依此类推。
首先确定一下最终目标:生成批处理语句,格式是 ren 旧文件名 新文件名。
这时候就该祭出EXCEL大杀器了(当然在程序里给url跑个循环,在循环里生成批处理语句也一样),把URL粘贴到A列,B列用公式填充 =”ren “&RIGHT(A1,36)&” “&ROW()&”.jpg” ,就可以生成批量重命名所需要的语句(right函数的长度36来自于32位uuid加上后缀名.jpg,一共36个字符)。
如果这个公式一时半会憋不出来,或者文件名长度不固定也没关系,按下面这个方法操作就可以:
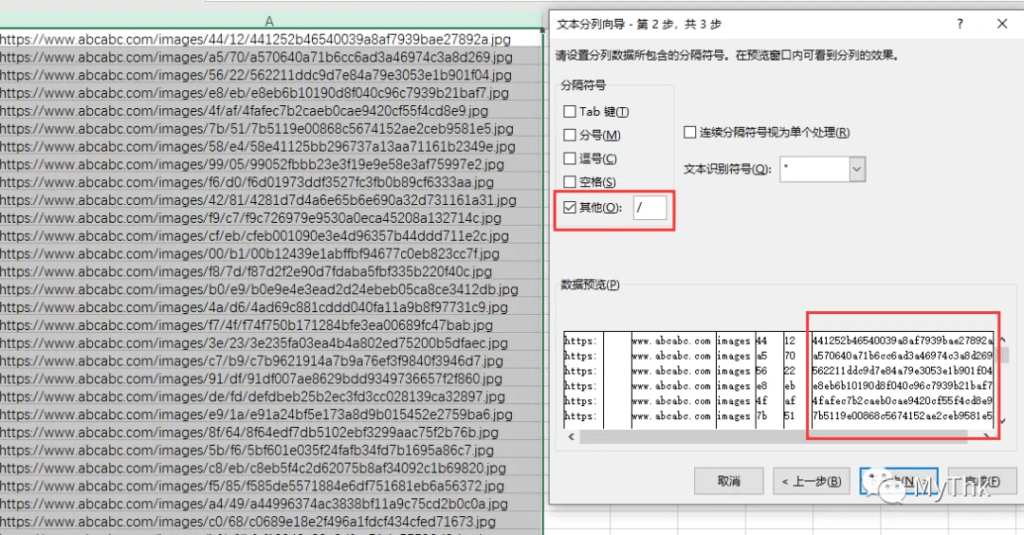
- 选中A列,分列,分列的依据是/符号,因为长度不管怎么变,它的结构都是固定的,最后一列一定是文件名(这个案例的URL分完列以后,文件名在G列);
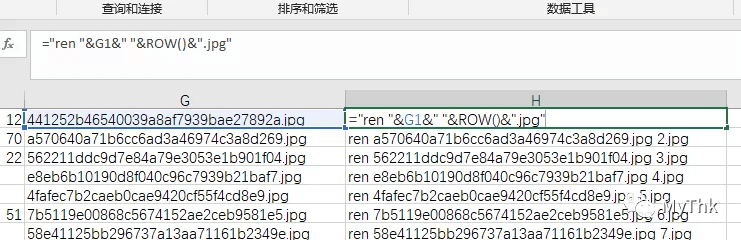
- 在H列用公式 =”ren “&G1&” “&ROW()&”.jpg” 进行填充,即可得到重命名的批处理语句。
excel生成批处理语句的时候,需要注意如下事项:
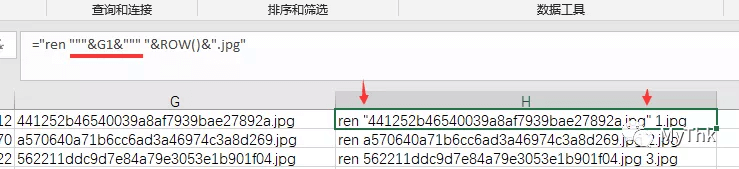
- 命令、开关、参数之间要有空格;
- 如果某个参数(尤其是文件名)包含空格,需要将这个参数值用双引号包起来,如果G1的文件名是 文件 名 .jpg,公式=”ren “&G1&” “&ROW()&”.jpg” 将生成一条语法错误的语句,所以碰到类似的需求建议一律添加引号,这样的话可以100%避免这类错误。
static void Main(string[] args)
{
string ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36";
using WebClient client = new WebClient();
for (int i = 2; i < 45; i++)
{
client.Headers["User-Agnet"] = ua;
string resp = client.DownloadString($"http://www.abcabc.com/index.php/pages/181818?Pages_page={i}");
string img = Regex.Match(resp, @"(?<=.*)https.*?(?=""\s+id=""image"")").Value;
Console.WriteLine($@"{i}\{img}\ren {Regex.Match(img, "[a-z0-9]+.jpg").Value} {i}.jpg");
//打印结果分三个部分:页码,url,重命名语句,中间以\符号分隔,
//这样就可以在粘贴到EXCEL后,用\符号进行数据分列。
//第二列是URL,批量下载后,把第三列复制到命令提示符进行重命名
Thread.Sleep(500);
//稍微延个时,过快的话很可能触发某些网站的反爬策略
//因为下载网页源码往往会在瞬间完成;
//这一点不像浏览器,获取到源码后还要下载资源,并把页面渲染出来
//网络稍微不稳定或者资源体积过大,整个过程将极为耗时。
}
Console.WriteLine("OK");
Console.Read();
}第二个案例
这个例子比上面要简单得多,所有图片全在一个页面里,全程调试工具就能完成:F12打开调试工具,遍历所有img对象并拿到src属性里的url,扔到迅雷的批量任务即可,甚至严格来说这个都不能算是爬虫,虽然没什么挑战性,但也是一种特别典型的场景。
流程还是一样:分析页面,提取URL,下载。
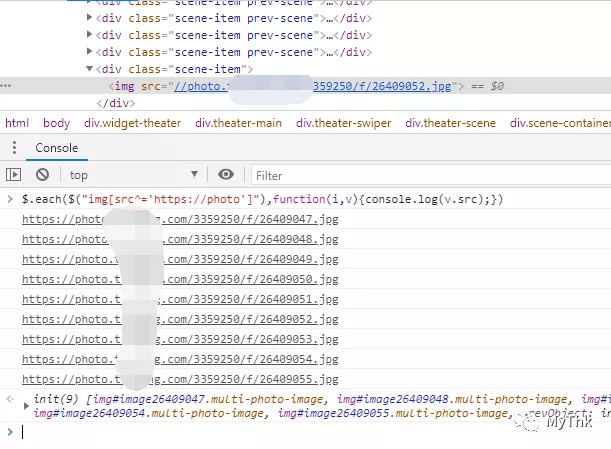
先拿到所有img,遍历打印src的值,观察特征可以发现所有符合要求的图片都以https://photo开头。
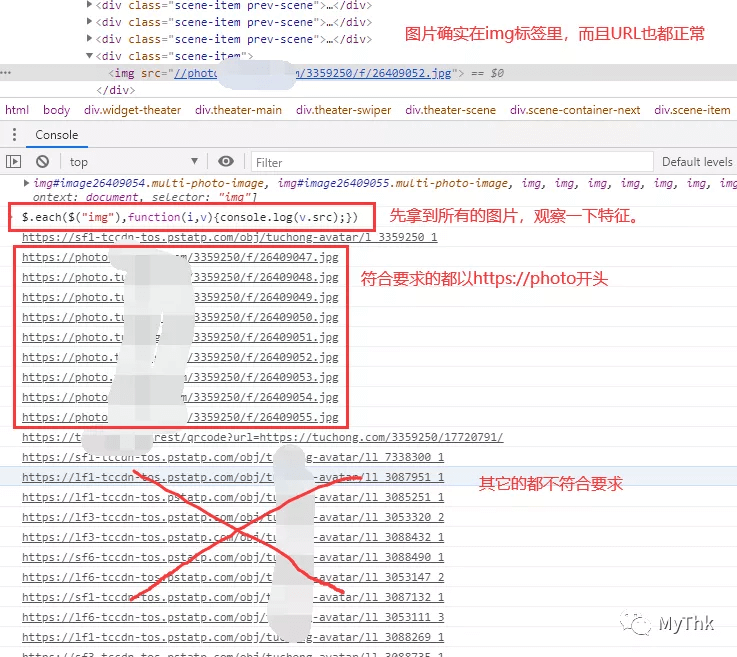
在选择器上加个条件,以https://photo开头,得到符合要求的图片,复制地址下载即可。
放一张爬下来的图片治愈一下
