原理:
模拟浏览器行为,请求目标资源,获取到需要的内容后,视需求再进一步提炼(一般使用字符串处理得到需要的信息)。
需要具备哪些知识:
- HTTP通信原理:需要理解HTTPRequest,HTTPResponse,HTTPHeader,Cookie,Session,Content-Type,Form提交,编码,谓词(一般只需要用到GET和POST),HTTP状态码。
- 前端知识:主要用来分析网页,不需要了解多深,只需要知道基本的HTML元素,HTML元素的id、name、tag等属性,对CSS有大概的了解;需要懂得使用浏览器DevTools查看网页元素,查看Network中的通信,查看Request和Response的详情;某些场景里,需要对JS有一定了解。
- 一种编程语言:需要了解如何通过httpclient发送Get和Post请求,并获取服务器响应,需要懂得如何进行字符串处理(对正则表达式有个基本了解,能够实际使用起来的话,帮助会很大)。
场景一:批量下载网站上的二进制文件,这种需求不需要额外处理,直接保存到文件就完成任务了;
场景二:希望提取网页中的某些信息,这种需求需要在得到网页源码后,通过字符串处理,摘出所需要的内容,这部分工作的重点不光是如何获取到网页源码,还在于如何对HTML源码进行解析,精确提取关键信息。
demo:
- 爬虫一:直接抓取页面
- 爬虫二:带user-agent检测的页面
- 爬虫三:带翻页的列表
- 爬虫四:要求登录的页面
- 爬虫五:利用终极利器Selenium执行批处理操作
爬虫一:直接抓取页面
- 网站页面:http://nginx.org/
- 目标内容:看看nginx news有哪些目录
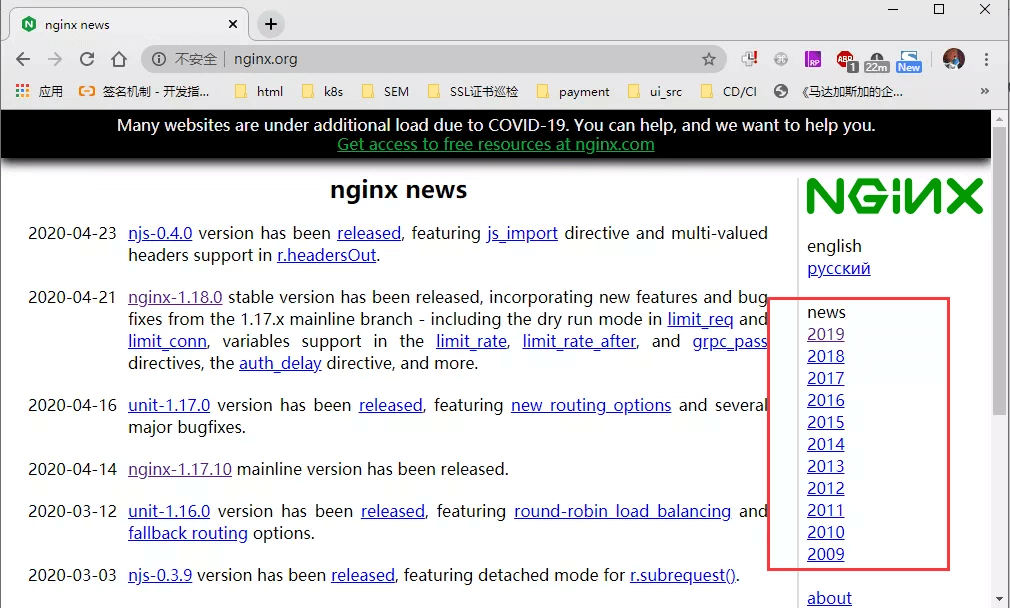
- 步骤一:踩点
首先要做的一件事,就是分析目标网页,查看资源是如何呈现的,这一步完成后,才知道应该使用哪种技术去下载页面,以及如何去提取网页中的内容。
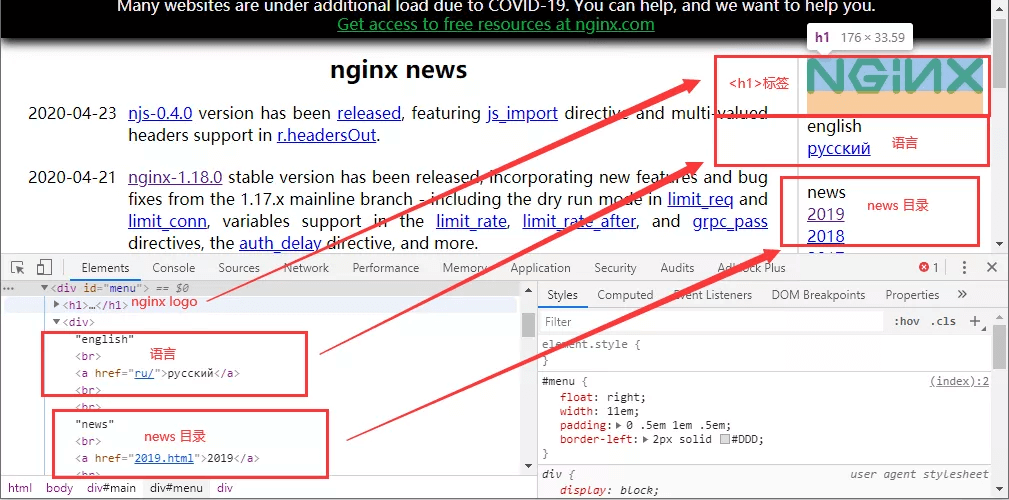
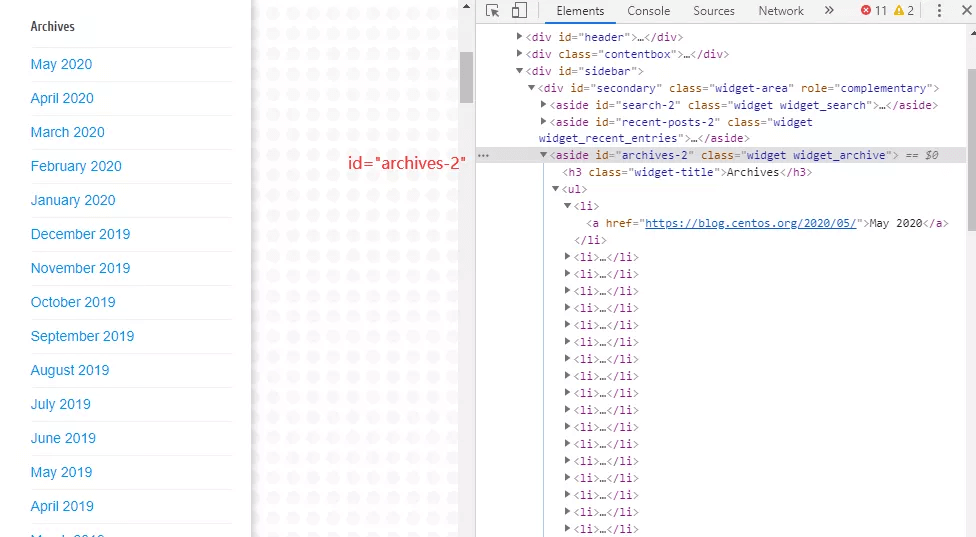
通过网页分析我们可以发现,news目录位于body -> div#main -> div#menu下面,而这个div#menu又包含了其它的一些信息,比如语言链接,和下面的about等不相关的栏目。
- 步骤二:下载页面
下载页面的方法挺多,命令行工具有curl, wget等等,或者支持http交互的语言(纯TCP也能实现,但是需要自己构造HTTP消息发到服务器,同时也要额外解析一下服务器返回的响应内容),这个地方八仙过海各显神通了。 - 步骤三:提取内容
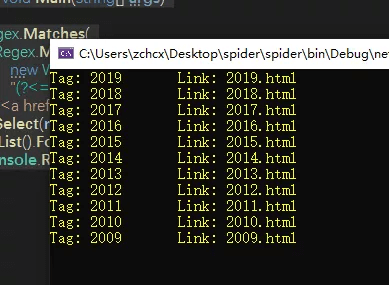
static void Main(string[] args)
{
Regex.Matches(
Regex.Match(
new WebClient().DownloadString("http://nginx.org/"),
"(?<=id=\"menu.*?news).*</div>").Value,
"<a href=\"(.*?)\">(\\d{4})</a>").
Select(m => $"Tag: {m.Groups[2]}\tLink: {m.Groups[1]}").
ToList().ForEach(s => Console.WriteLine(s));
Console.ReadLine();
}
爬虫二:带user-agent检测的页面
- 网站页面:https://www.ip.cn/
User-Agent是浏览器向网站发送的一个身份标识,这个标识记录了浏览器的类型、操作系统环境、内核、版本等信息。服务器可以根据这些信息做相应的动作,比如识别搜索引擎蜘蛛(正规搜索引擎蜘蛛都会主动向网站表明自己的身份)、统计本站访客的操作系统占比、PC/移动占比、根据不同的浏览器展示不同的外观、根据不同的操作系统跳转到对应系统版本的软件下载链接等等。
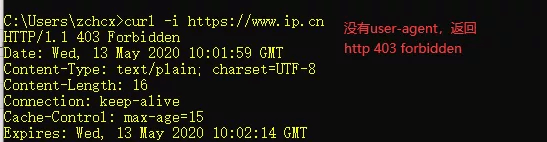
这个参数设计之初,其目的就是为了提升用户浏览体验(以及浏览器厂商之间的恶性竞争,正因为这个原因,现在user-agent已经不算一个很重要的东西了),而网站加入user-agent检测,也可以初步区分出访客是机器人还是真实用户(user-agent可以伪造,所以这个不是决定性证据,会有漏网的情况,但如果没有user-agent,则可以100%断定不是正常访客)。
ip.cn这个网站就是如此,如果没有user-agent,它就不会正常输出内容,而是报一个403错误提示。
- 目标信息:查看本机的公网IP信息(地址、位置、geoip记录)。通过查看网页源码就可以发现这三条信息被三个<code>标签所包含。
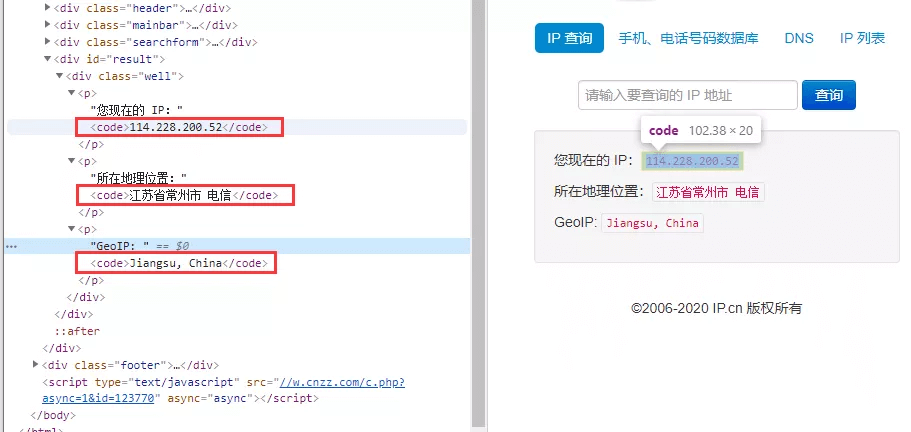
- 下载和提取
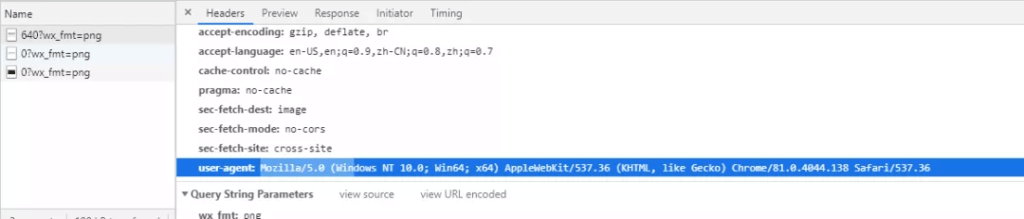
WebClient client = new WebClient();
client.Headers["user-agent"] =
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36";
string result = client.DownloadString("https://www.ip.cn");
var matches = Regex.Matches(result, "(?<=<code>).*?(?=</code>)");
for (int i = 0; i < 3; i++)
Console.WriteLine(
new string[] { "ip", "位置", "geoip" }[i] +$"\t{matches[i].Value}");
Console.ReadLine();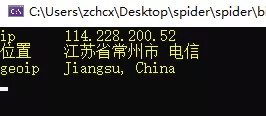
爬虫三:带翻页的列表
有的时候,我们会碰到抓取某个栏目所有页面的需求,例如“新闻”栏目下所有新闻,这种场景里,往往新闻会有数十上百条,新闻列表也会有数十页之多。碰到这种需求,需要拆解一下任务:第一步,获取所有新闻列表页面,并保存新闻链接;第二步按新闻链接访问页面,抓取实际的新闻页面。
- 网站页面:https://blog.centos.org/
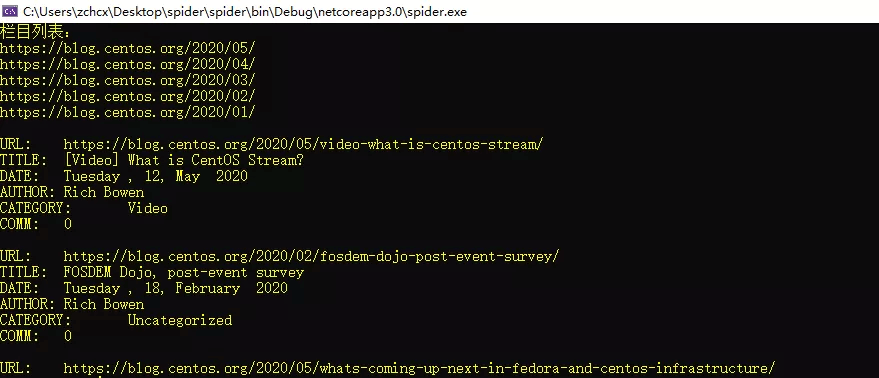
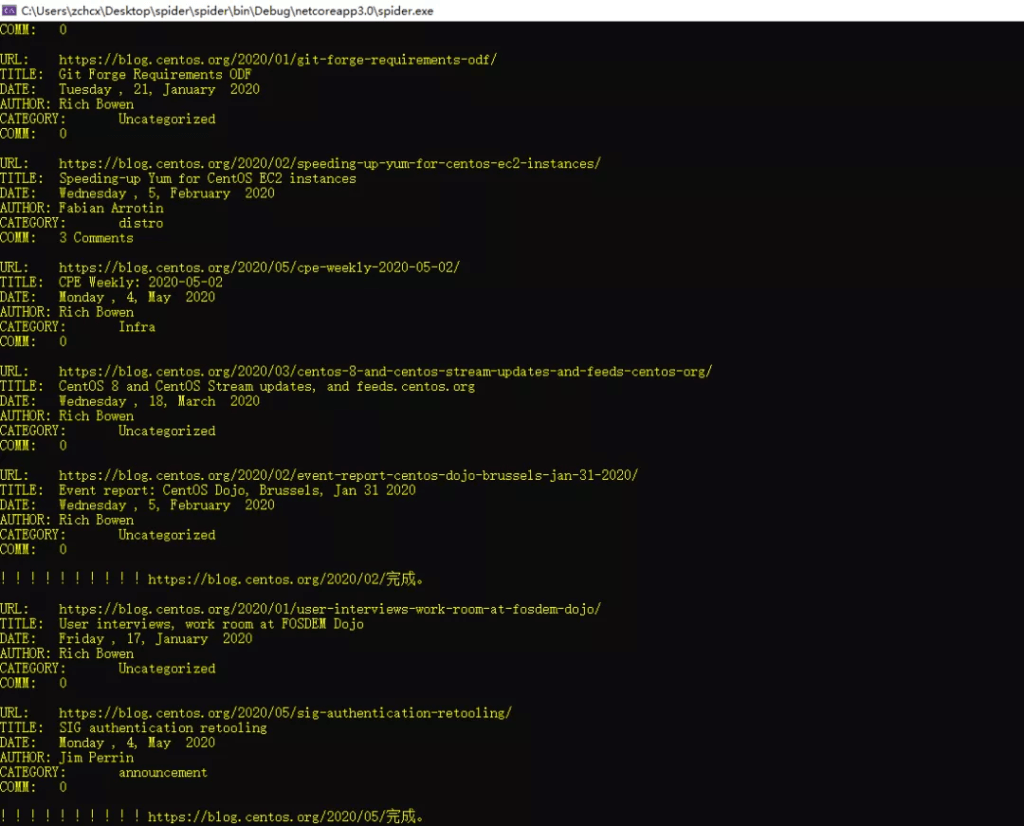
- 抓取内容:2020年的所有博文(只提取文章标题、分类、作者、时间、评论数量,文章内容我就不保存了)
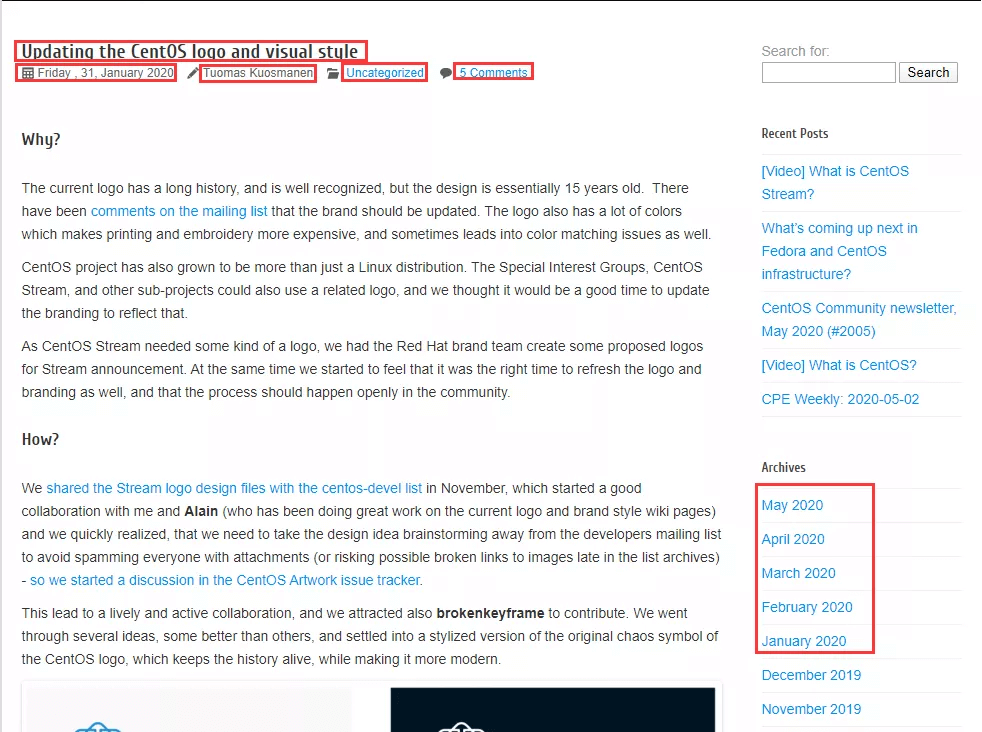
- 完整的月份列表可以在任一个页面的右侧找到,因为只是演示,所以只抓取2020年一月到五月的数据。
- 第一步,访问blog首页拿到所有Archive,并提取2020年的月份;
- 第二步,访问每个月的列表页面并读取每个列表页面的新闻链接;
如果当前列表页面有“Older Posts”这个链接,说明不止一页,需要继续访问下一页,直到不再出现“Older Posts”,说明到达该最后一页列表;
- 第三步,到这一步,手里就已经有了所需月份的、所有新闻页面的链接,慢慢后台批量处理吧。
class Program
{
static void Main(string[] args)
{
var result = GetContent("https://blog.centos.org");
if (!result.succ)
{
Console.WriteLine("无法打开网站。");
}
else
{
string html =
Regex.Match(result.code, "archives-2.*?</ul>", RegexOptions.Singleline).Value;
var months =
Regex.Matches(html, "(?<=<li><a href=').*?(?='>.*?</a>)").
Select(m => m.Value).Where(url => url.Contains("/2020/"));
Console.WriteLine("栏目列表:\r\n" + string.Join("\r\n", months) + "\r\n");
foreach (var month in months)
{
var _month = month;
Task.Run(() =>
{
List<string> news = new List<string>();
GetMonth(_month, ref news);
news.ForEach(u => GetNews(u));
Console.WriteLine($"!!!!!!!!!!{_month}完成。\r\n");
});
}
}
Console.ReadLine();
}
static (string code, bool succ) GetContent(string url)
{
WebClient client = new WebClient();
client.Headers["user-agent"] =
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36";
try
{
return (client.DownloadString(url), true);
}
catch (Exception)
{
return ("", false);
}
}
/// <summary>
/// 获取月份所有新闻的链接
/// </summary>
/// <param name="url">指定月份的新闻首页</param>
/// <returns></returns>
static void GetMonth(string url, ref List<string> news)
{
var result = GetContent(url);
if (result.succ)
{
var matches = Regex.Matches(
result.code,
"(?<=boxh3.*?<a href=\\\")https://blog.*?(?=\\\")");
foreach (Match m in matches) news.Add(m.Value);
if (result.code.Contains("id=\"older-posts\""))
{
string nextpage =
Regex.Match(result.code, "(?<=older-posts.*?)https://.*?(?=\")").Value;
GetMonth(nextpage, ref news);
}
}
else
{
GetMonth(url, ref news); //失败时,重新来一遍
}
}
/// <summary>
/// 根据新闻URL,获取标题、作者、日期、分类、回复数量
/// </summary>
/// <param name="url"></param>
static void GetNews(string url)
{
var html = GetContent(url);
if (html.succ)
{
string segment =
Regex.Match(html.code, "loophead.*?(?<=</div>)", RegexOptions.Singleline).Value;
string title =
Regex.Match(segment, "(?<=<h2.*?>).*?(?=<)").Value;
string date =
Regex.Match(segment, "(?<=class=\\\"postcalendar.*?>).*?(?=<)").Value.Trim();
string author =
Regex.Match(segment, "(?<=class=\\\"postauthor.*?>).*?(?=<)").Value.Trim();
string category =
Regex.Match(segment, "(?<=class=\\\"postcategory.*?><a.*?>).*?(?=<)").Value.Trim();
string comments =
Regex.Match(segment, "\\d+\\s+Comments").Value;
if (string.IsNullOrEmpty(comments)) comments = "0";
Console.WriteLine(
$"URL:\t{url}\r\nTITLE:\t{title}\r\nDATE:\t{date}\r\nAUTHOR:\t{author}\r\n" +
$"CATEGORY:\t{category}\r\nCOMM:\t{comments}\r\n");
}
else
{
GetNews(url);
}
}
}
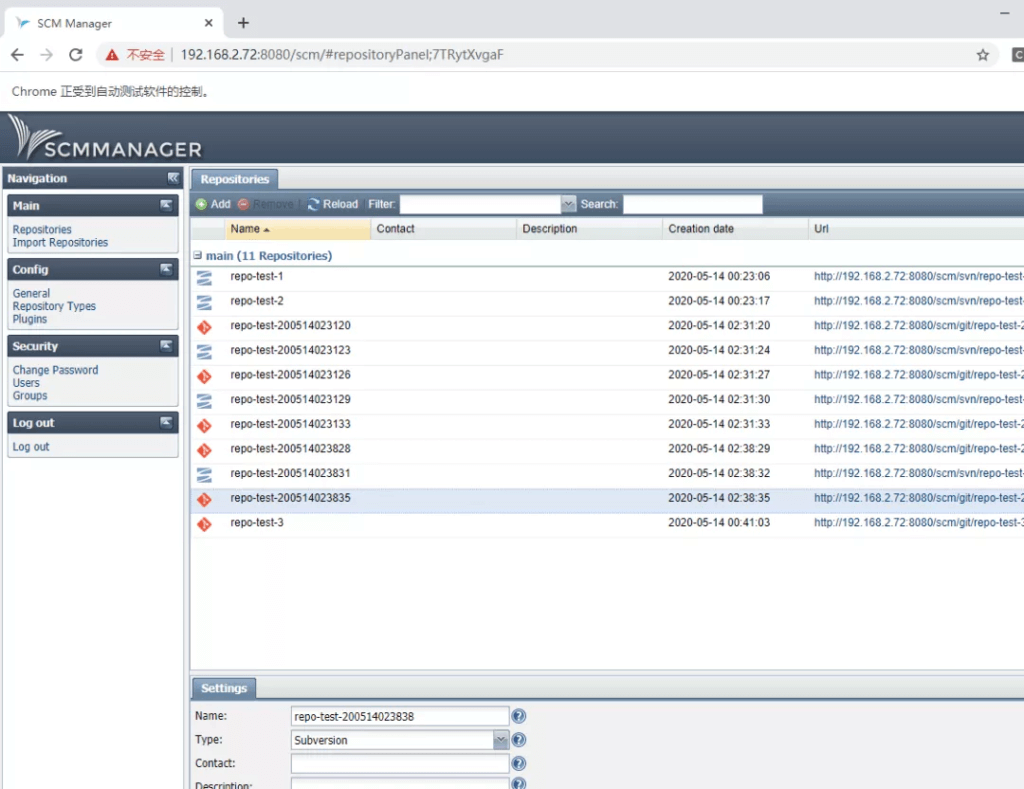
爬虫四:要求登录的页面
- 测试站点:某scm-manager站点
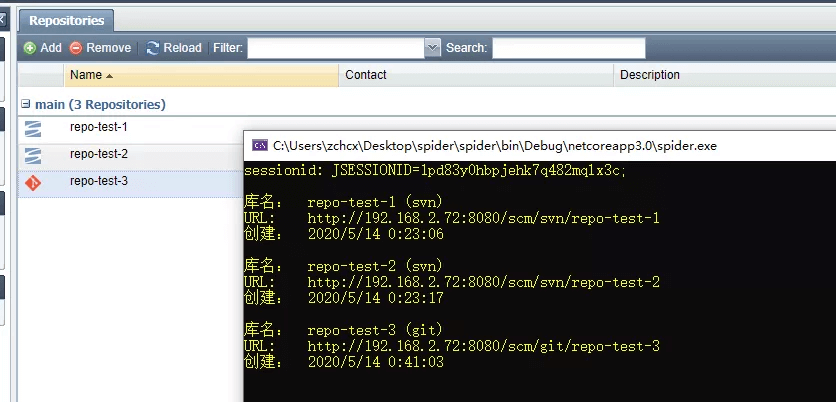
- 目标内容:获取服务器所有代码库
- 步骤一:登录服务器,获取SESSION_ID;
- 步骤二:访问代码库列表,获取内容。
class Program
{
static void Main(string[] args)
{
string urlbase = "http://192.168.2.72:8080";
WebClient client = new WebClient();
client.Headers["Content-Type"] = "application/x-www-form-urlencoded";
string result =
client.UploadString(
$"{urlbase}/scm/api/rest/authentication/login",
"username=scmadmin&password=scmadmin");
string sessionid = Regex.Match(
client.ResponseHeaders["Set-Cookie"],
"JSESSIONID=.*?;", RegexOptions.IgnoreCase).Value;
Console.WriteLine($"sessionid: {sessionid}\r\n");
client.Headers["Cookie"] = sessionid;
client.Headers["Accept"] = "application/json;charset=UTF-8";
var repos =
JsonConvert.DeserializeObject<List<repo>>(
client.DownloadString($"{urlbase}/scm/api/rest/repositories"));
repos.ForEach(
r => Console.WriteLine($"库名:\t{r.name}\r\n类型:\t{r.type}\r\n" +
$"创建:\t{DateTime.Parse("1970/1/1 08:00").AddMilliseconds(r.creationDate)}\r\n"));
Console.ReadLine();
}
}
class repo
{
public long creationDate { get; set; }
public string name { get; set; }
public string type;
}
爬虫五:几乎什么都能抓、但并不仅仅用于爬虫的终极利器Selenium
selenium是一套webdriver组件,支持Chrome, Firefox, IE, PhantomJS。本文以Chrome做演示,还是用爬虫四中的网站为例,登录并创建五个repo。
因为网站HTML代码由服务器源源不断向webdriver控制的浏览器主动推送过来,所以无论以什么频率,在什么时间查看浏览器里的源代码,都只是读取已经保存下来的本地资源,服务器无法感知,没有任何负面影响。
由于需要渲染页面,和不断地检测页面加载是否完成,这种方式效率更低,但是由于它使用的是真实浏览器,而不再是“模拟”,并且可以精准地进行页面交互,selenium能够更轻松地胜任更多更复杂的任务,一般自动化测试都倾向于使用它,而爬虫则更多地考虑直接用http client模拟。
在使用selenium时,首先需要对业务全程有充分的了解,知道每一步会遇到什么,如何处理,弄清楚以后再将所需的操作翻译成浏览器的操作指令(本质上就是用自己偏爱的语言编写操作浏览器的宏)。
而操作指令所包含的内容,就是根据条件进行判断和操作:在何种条件下,找到哪个/哪些网页元素,进行何种操作。这一步的关键在于如何找到目标元素,selenium可以通过LinkText,Tagname, classname, Id, XPath等各种手段定位元素,具体根据何种方式定位,根据实际情况选择即可,往往有多种方式可以实现相同的目的。
Nuget库:Selenium.WebDriver、Selenium.WebDriver.ChromeDriver
操作流程:
- 打开页面并等待加载完成(通过关键的网页元素是否存在来判断,比如确定登录页面是否加载完成,就可以拿用户名和密码输入框,以及登录按钮作依据);
- 填入用户名、密码,点击登录按钮;
- 点击Repositories链接,进入代码库列表页面;
- 点击Add按钮打开表单;
- 填写表单中的库名、库类型;
- 点击Ok按钮提交。
class Program
{
static void Main(string[] args)
{
IWebDriver browser = new ChromeDriver();
browser.Navigate().GoToUrl("http://192.168.2.72:8080/scm/");
//网页加载过程中循环查看源码,直到出现用户名输入框、密码输入框和登录按钮为止认为
//加载完成,这个认定标准由自己按需制定
while (!browser.PageSource.Contains("id=\"loginButton\"") ||
!browser.PageSource.Contains("type=\"password") ||
!browser.PageSource.Contains("id=\"username")) Thread.Sleep(2000);
//填表,提交
browser.FindElement(By.Id("username")).SendKeys("scmadmin");
browser.FindElement(By.Name("password")).SendKeys("scmadmin");
Thread.Sleep(500);//填完必填项后,等半秒,提交按钮解除禁用状态再点击
browser.FindElement(By.ClassName("x-btn-text")).Click();
//点击进入Repositories界面
while (!browser.PageSource.Contains("Repositories</a>")) Thread.Sleep(2000);
browser.FindElement(By.LinkText("Repositories")).Click();
for (int i = 0; i < 5; i++)
{
//点击提交按钮
while (!browser.PageSource.Contains("resources/images/add.png")) Thread.Sleep(2000);
browser.FindElement(By.Id("repositoryAddButton")).FindElement(By.TagName("tbody")).
FindElements(By.TagName("button"))[0].Click();
while (!browser.PageSource.Contains("id=\"repositoryName\"") ||
!browser.PageSource.Contains("id=\"repositoryType") ||
!browser.PageSource.Contains(">Ok</button>")) Thread.Sleep(2000);
//填写库名
browser.FindElement(By.Id("repositoryName")).SendKeys(
"repo-test-" + DateTime.Now.ToString("yyMMddHHmmss"));
browser.FindElement(By.Id("repositoryType")).Click();
while (!browser.PageSource.Contains("x-combo-list-item")) Thread.Sleep(2000);
//点击下拉菜单里的Subversion
string repotype = (i & 1) == 1 ? "Subversion" : "Git";
browser.FindElements(By.ClassName("x-combo-list-item")).
Where(e => e.Text == repotype).First().Click();
Thread.Sleep(500);//填完必填项后,等半秒,提交按钮解除禁用状态再点击
browser.FindElement(By.XPath("//button[text()='Ok']")).Click();
Thread.Sleep(2000);
}
}
}